6 Understanding the Machine Learning Analytical Cycle
6.1 Basic Architecture of the Analytical Cycle in Machine Learning
The machine learning analytical cycle consists of multiple interconnected phases, each playing a vital role in ensuring that data is utilized effectively to build accurate predictive models. The key architectural components include:
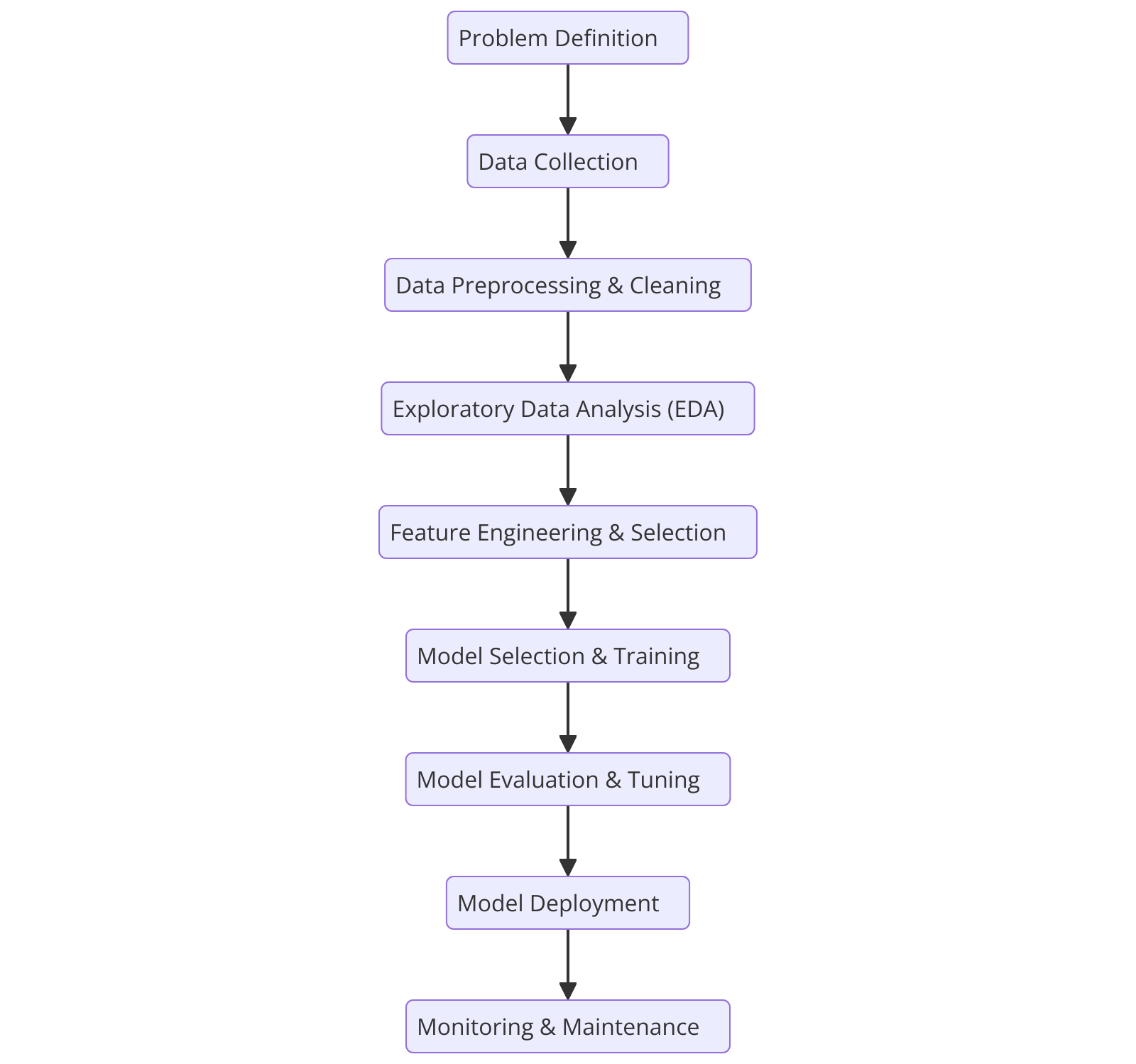
Step 1: Problem Definition
- Clearly define the business or research problem that needs to be addressed.
- Determine the type of ML model (Supervised, Unsupervised, Reinforcement Learning) required.
- Example: Predicting customer churn in a telecom company.
Step 2: Data Collection
- Gather relevant raw data from multiple sources such as databases, APIs, web scraping, IoT sensors, etc.
- Ensure data relevance, quality, and availability for training the model.
- Example: Collecting transaction history, customer demographics, and engagement data for churn prediction.
Step 3: Data Preprocessing & Cleaning
- Handle missing values, duplicates, and outliers.
- Convert categorical variables into numerical form (dummy encoding, label encoding).
- Normalize or standardize data to bring all variables to a common scale.
- Example: Cleaning customer data by filling missing values and standardizing income levels.
Step 4: Exploratory Data Analysis (EDA)
- Use statistical methods and visualization tools to understand patterns, trends, and correlations.
- Identify significant variables that influence the outcome.
- Example: Using scatter plots and correlation matrices to identify factors affecting customer churn.
Step 5: Feature Engineering & Selection
- Transform raw data into meaningful features that improve model performance.
- Apply feature selection techniques (filter methods, wrapper methods, embedded methods) to remove redundant features.
- Example: Creating a new feature “average monthly spend” from transaction history data.
Step 6: Model Selection & Training
- Choose the appropriate machine learning algorithm (e.g., Decision Trees, Random Forest, Neural Networks).
- Split data into training and testing sets (e.g., 80%-20% split).
- Train the model using optimization techniques (Gradient Descent, Adam Optimizer).
- Example: Training a Random Forest model to predict churn probability.
Step 7: Model Evaluation & Tuning
- Use evaluation metrics like accuracy, precision, recall, F1-score, RMSE (Root Mean Square Error) to measure model performance.
- Perform hyperparameter tuning (Grid Search, Random Search) to optimize the model.
- Example: Adjusting the number of trees in a Random Forest to improve prediction accuracy.
Step 8: Model Deployment
- Deploy the trained ML model into a real-world environment (Web app, API, cloud-based service).
- Ensure integration with business processes and monitor performance.
- Example: Deploying a churn prediction model on a company’s CRM system.
Step 9: Monitoring & Maintenance
- Continuously track model performance to detect drift or degradation.
- Update the model periodically with new data to maintain accuracy.
- Example: Monitoring if the churn prediction model remains accurate over time and retraining it when necessary.
6.2 Key Components of an Analytical Process
The machine learning analytical process consists of essential building blocks that ensure data-driven insights are effectively generated.

1. Data Acquisition
- Collecting data from internal and external sources.
- Example: User logs, transactional records, IoT sensor data.
2. Data Preprocessing
- Cleaning, handling missing values, and transforming raw data into structured formats.
- Example: Removing duplicate entries, normalizing financial transactions.
3. Feature Engineering
- Creating new meaningful features or selecting important ones.
- Example: Converting timestamps into “day of the week” to analyze sales patterns.
4. Model Development
- Training ML models using statistical techniques and deep learning architectures.
- Example: Training a neural network to classify images.
5. Model Validation
- Checking the model’s effectiveness using metrics and test datasets.
- Example: Evaluating a credit scoring model using AUC-ROC curves.
6. Model Deployment
- Implementing the model in real-world applications.
- Example: Deploying a fraud detection model in a banking system.
7. Continuous Learning & Improvement
- Updating the model as new data becomes available.
- Example: An e-commerce recommendation system that adapts to new customer preferences.